

快速安装 WSL2-Ubuntu 并配置 Hadoop,Spark 环境
本文最后更新于 2024-12-14,当前距离文章发布(更新)已经超过365天,文章内容可能已经过时,请注意甄别。
相关资源下载
夸克网盘
提取码:无
1.安装WSL2&更新内核组件
确认系统版本
以下版本可以使用WSL2:
Windows 11
Windows 10 2004或更高版本
Windows 10 1903/1909 并且安装了 KB4566116
启用WSL、虚拟机平台
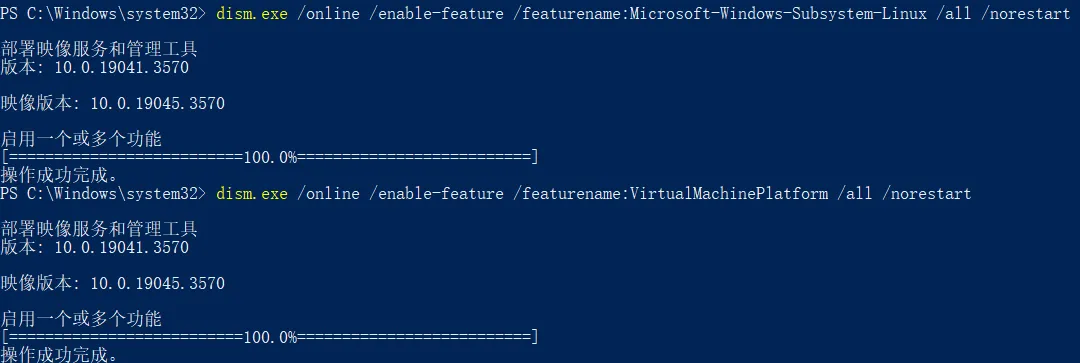
以管理员身份启动Powershell,运行以下代码
适用于Windows11/Windows10(2004+)
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart适用于Windows10(1903/1909)
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
Enable-WindowsOptionalFeature -Online -FeatureName VirtualMachinePlatform -NoRestart正确执行如图所示
重新启动系统以确保功能被安装
测试WSL是否已安装并切换默认版本
打开cmd/Powershell,使用命令wsl,如果功能正常,应当显示

使用命令来更改WSL默认版本到WSL2
wsl --set-default-version 2正常运行结果:

更新WSL2 Linux内核
打开WSL2 Linux内核更新包并安装,一路next就好。
(如果找不到,从这里下载)
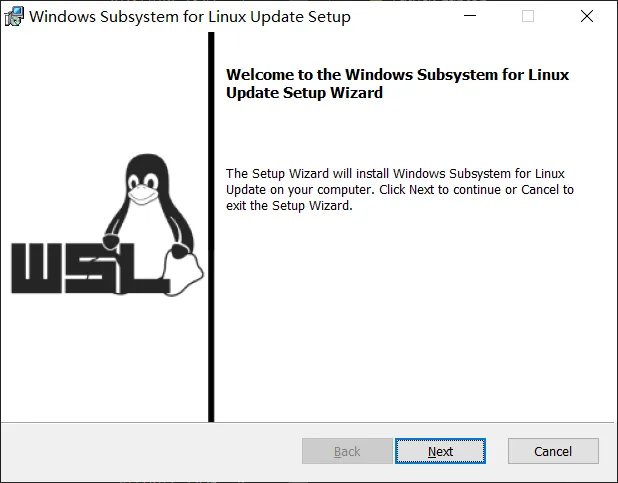
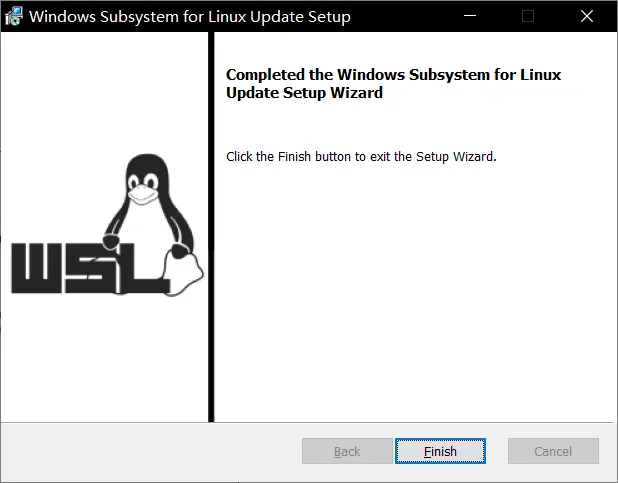
安装完成后如上图所示。
2.安装Ubuntu子系统
(推荐)【方法一】离线安装Ubuntu 22.04 LTS AppxBundle
在安装包位置打开Powershell,执行以下命令:
Add-AppPackage .\CanonicalGroupLimited.Ubuntu_2204.2.33.0_neutral_~_79rhkp1fndgsc.AppxBundle如果开始菜单内能够看到一个Ubuntu应用,且Powershell窗口没有报错,那么代表安装成功。
安装包文件已经在文首的网盘链接中提供
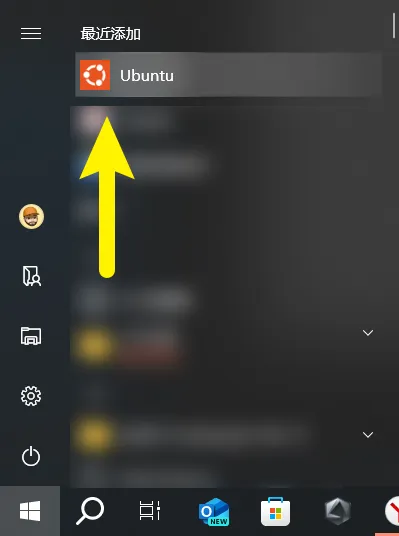
如果方法一配置没有问题,你可以跳转到3.配置开发环境部分,否则请尝试方法二。
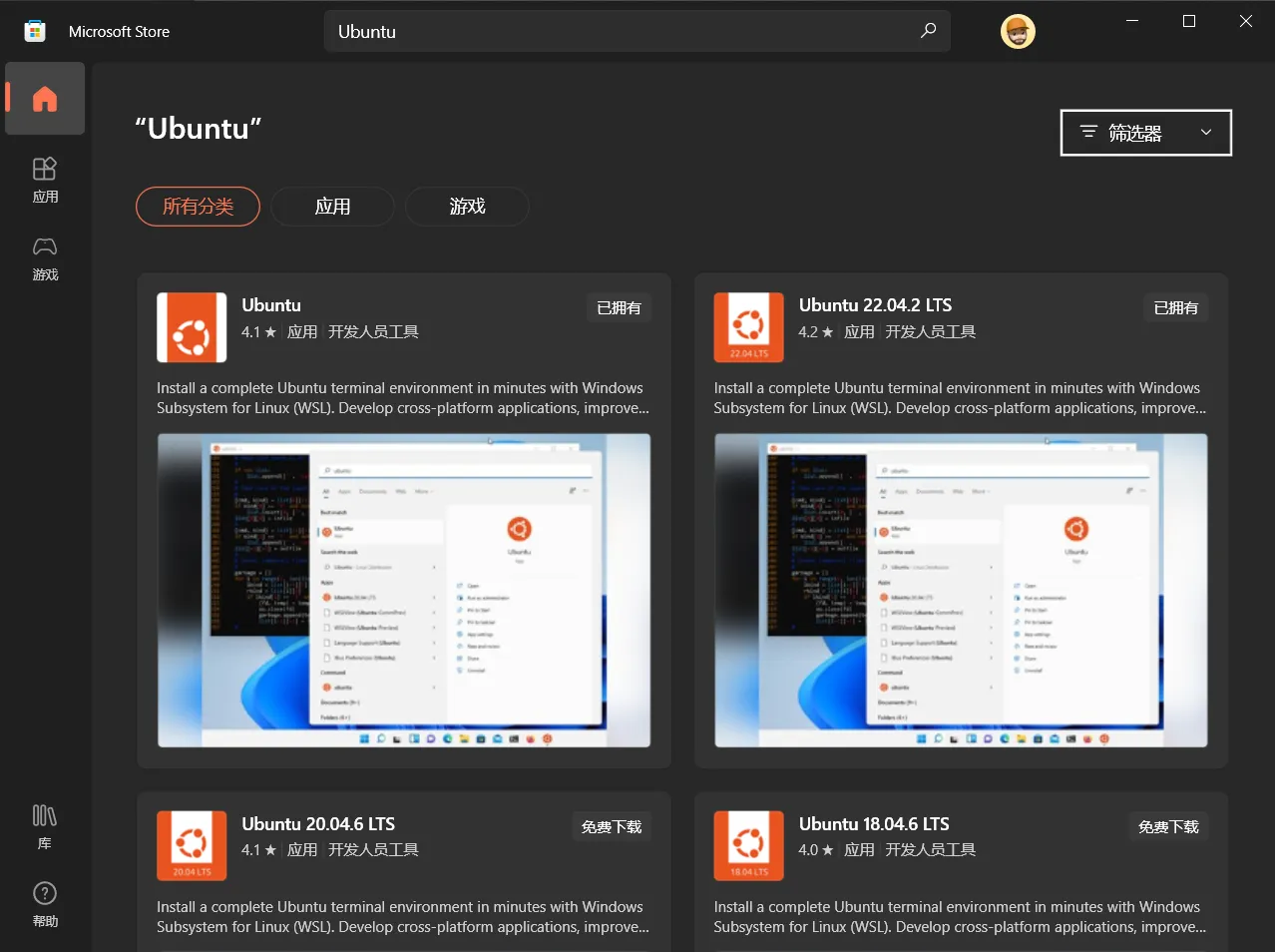
【方法二】从Microsoft Store安装Ubuntu
打开Microsoft Store,搜索Ubuntu,安装你喜欢的版本。
通常,选择第一个“Ubuntu”(不带版本后缀)。
如果选择Ubuntu 22.04.2 LTS,后续执行某些命令时,需要使用ubuntu2204而不是ubuntu,请自行斟酌。
3.配置开发环境(OpenJDK8,Python,Hadoop,Spark)
(推荐)【方法一】导入WSL镜像
此方法使用已经配置好环境的WSL镜像,一步导入即可使用。
安装包文件已经在文首的网盘链接中提供
定位到镜像保存的文件夹,打开cmd/Powershell,执行命令:
wsl --unregister Ubuntu
mkdir C:\WSL\Ubuntu
wsl --import Ubuntu C:\WSL\Ubuntu .\Ubuntu_22.04_LTS_hadoop3.3.6_spark3.5.0_python3.10.tarUbuntu 是导入后此WSL系统的名称,如无特殊需要不建议更改,后续教程都使用此名称
C:\WSL\Ubuntu 是导入子系统的位置,如果C盘空间不足可以更改到其他磁盘,但务必注意不要删除或使用第三方软件自己修改。
Ubuntu_22.04_LTS_hadoop3.3.6__spark3.5.0_python3.10.tar WSL系统镜像文件的名称,如果不在当前目录下需要自己修改路径
如果命令执行没有出错,将不会有任何提示:

执行以下命令,查看当前已安装的WSL子系统
wsl --list
由于导入的WSL镜像默认登录用户为root,将其作为开发环境是不安全的,需要修改:
ubuntu config --default-user linuxisthebest建议一定要重新设置用户密码:
此密码需要牢记,但不要过于简单
如果不重新设置密码,默认的密码为12345678
wsl -u root
passwd linuxisthebest
# 执行完上述命令后,输入两次新密码
# 通常在Linux系统中输入密码时,是不会显示密码文本或任何占位符(如***)
# 此处是WSL系统,因此也不会显示,直接输入即可
如果方法一配置没有问题,你可以跳转到PyCharm配置部分,否则请尝试方法二。
【方法二】手动配置环境
适用于对Linux版本或是软件版本有要求的开发、高级用户,或是你希望锻炼一下自己的动手能力/解决问题能力。
由于篇幅过长,另起新篇:从0开始配置WSL开发环境(Hadoop,Spark)
4.PyCharm配置WSL-Python解释器
安装PyCharm Professional Edition
社区版(Community)不支持使用WSL作为解释器,需要安装Pro版本,这里提供安装和破解教程。
如果聪明的你已经申请到了@*.edu.cn的邮箱,那么你可以使用此邮箱免费获得JetBrains专业版本软件的使用权限,而不需要破解,相对于破解软件,我更推荐这种方法。
首先,对原有的PyCharm进行彻底卸载,删除缓存、数据。

所需资源内已经准备好了pycharm-professional-2023.2.3.exe,直接安装即可,Pro版本也可以在JetBrains官网免费下载:https://www.jetbrains.com/pycharm/download/download-thanks.html?platform=windows
获得Pro版本使用授权
如果你还没有@*.edu.cn的邮箱,我强烈建议你去教务网申请一个,并以此获得免费的Jetbrains专业软件授权,使用正版授权的软件能减少很多不必要的麻烦。
不知道如何申请edu邮箱?->参见学校教务网
不知道如何通过edu邮箱获得免费专业授权?->搜索引擎搜索关键词“edu邮箱"“JetBrains”
如果你坚持要进行破解,请继续往下看:
文件已经在文首的网盘链接中提供
复制 JetBrainsCrack
将此文件夹复制到C盘根目录下。
当然,也可以是其他盘或目录,但路径不要包含任何空格或中文。
运行破解脚本
进入JetBrainsCrack\scripts\,运行install-current-user.vbs

等待脚本运行...
显示 Done. 代表运行完毕。
打开PyCharm输入激活码
EUWT4EE9X2-eyJsaWNlbnNlSWQiOiJFVVdUNEVFOVgyIiwibGljZW5zZWVOYW1lIjoic2lnbnVwIHNjb290ZXIiLCJhc3NpZ25lZU5hbWUiOiIiLCJhc3NpZ25lZUVtYWlsIjoiIiwibGljZW5zZVJlc3RyaWN0aW9uIjoiIiwiY2hlY2tDb25jdXJyZW50VXNlIjpmYWxzZSwicHJvZHVjdHMiOlt7ImNvZGUiOiJQU0kiLCJmYWxsYmFja0RhdGUiOiIyMDI1LTA4LTAxIiwicGFpZFVwVG8iOiIyMDI1LTA4LTAxIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IlBDIiwiZmFsbGJhY2tEYXRlIjoiMjAyNS0wOC0wMSIsInBhaWRVcFRvIjoiMjAyNS0wOC0wMSIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiUFBDIiwiZmFsbGJhY2tEYXRlIjoiMjAyNS0wOC0wMSIsInBhaWRVcFRvIjoiMjAyNS0wOC0wMSIsImV4dGVuZGVkIjp0cnVlfSx7ImNvZGUiOiJQV1MiLCJmYWxsYmFja0RhdGUiOiIyMDI1LTA4LTAxIiwicGFpZFVwVG8iOiIyMDI1LTA4LTAxIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IlBDV01QIiwiZmFsbGJhY2tEYXRlIjoiMjAyNS0wOC0wMSIsInBhaWRVcFRvIjoiMjAyNS0wOC0wMSIsImV4dGVuZGVkIjp0cnVlfV0sIm1ldGFkYXRhIjoiMDEyMDIyMDkwMlBTQU4wMDAwMDUiLCJoYXNoIjoiVFJJQUw6MzUzOTQ0NTE3IiwiZ3JhY2VQZXJpb2REYXlzIjo3LCJhdXRvUHJvbG9uZ2F0ZWQiOmZhbHNlLCJpc0F1dG9Qcm9sb25nYXRlZCI6ZmFsc2V9-FT9l1nyyF9EyNmlelrLP9rGtugZ6sEs3CkYIKqGgSi608LIamge623nLLjI8f6O4EdbCfjJcPXLxklUe1O/5ASO3JnbPFUBYUEebCWZPgPfIdjw7hfA1PsGUdw1SBvh4BEWCMVVJWVtc9ktE+gQ8ldugYjXs0s34xaWjjfolJn2V4f4lnnCv0pikF7Ig/Bsyd/8bsySBJ54Uy9dkEsBUFJzqYSfR7Z/xsrACGFgq96ZsifnAnnOvfGbRX8Q8IIu0zDbNh7smxOwrz2odmL72UaU51A5YaOcPSXRM9uyqCnSp/ENLzkQa/B9RNO+VA7kCsj3MlJWJp5Sotn5spyV+gA==-MIIETDCCAjSgAwIBAgIBDTANBgkqhkiG9w0BAQsFADAYMRYwFAYDVQQDDA1KZXRQcm9maWxlIENBMB4XDTIwMTAxOTA5MDU1M1oXDTIyMTAyMTA5MDU1M1owHzEdMBsGA1UEAwwUcHJvZDJ5LWZyb20tMjAyMDEwMTkwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQCUlaUFc1wf+CfY9wzFWEL2euKQ5nswqb57V8QZG7d7RoR6rwYUIXseTOAFq210oMEe++LCjzKDuqwDfsyhgDNTgZBPAaC4vUU2oy+XR+Fq8nBixWIsH668HeOnRK6RRhsr0rJzRB95aZ3EAPzBuQ2qPaNGm17pAX0Rd6MPRgjp75IWwI9eA6aMEdPQEVN7uyOtM5zSsjoj79Lbu1fjShOnQZuJcsV8tqnayeFkNzv2LTOlofU/Tbx502Ro073gGjoeRzNvrynAP03pL486P3KCAyiNPhDs2z8/COMrxRlZW5mfzo0xsK0dQGNH3UoG/9RVwHG4eS8LFpMTR9oetHZBAgMBAAGjgZkwgZYwCQYDVR0TBAIwADAdBgNVHQ4EFgQUJNoRIpb1hUHAk0foMSNM9MCEAv8wSAYDVR0jBEEwP4AUo562SGdCEjZBvW3gubSgUouX8bOhHKQaMBgxFjAUBgNVBAMMDUpldFByb2ZpbGUgQ0GCCQDSbLGDsoN54TATBgNVHSUEDDAKBggrBgEFBQcDATALBgNVHQ8EBAMCBaAwDQYJKoZIhvcNAQELBQADggIBABqRoNGxAQct9dQUFK8xqhiZaYPd30TlmCmSAaGJ0eBpvkVeqA2jGYhAQRqFiAlFC63JKvWvRZO1iRuWCEfUMkdqQ9VQPXziE/BlsOIgrL6RlJfuFcEZ8TK3syIfIGQZNCxYhLLUuet2HE6LJYPQ5c0jH4kDooRpcVZ4rBxNwddpctUO2te9UU5/FjhioZQsPvd92qOTsV+8Cyl2fvNhNKD1Uu9ff5AkVIQn4JU23ozdB/R5oUlebwaTE6WZNBs+TA/qPj+5/we9NH71WRB0hqUoLI2AKKyiPw++FtN4Su1vsdDlrAzDj9ILjpjJKA1ImuVcG329/WTYIKysZ1CWK3zATg9BeCUPAV1pQy8ToXOq+RSYen6winZ2OO93eyHv2Iw5kbn1dqfBw1BuTE29V2FJKicJSu8iEOpfoafwJISXmz1wnnWL3V/0NxTulfWsXugOoLfv0ZIBP1xH9kmf22jjQ2JiHhQZP7ZDsreRrOeIQ/c4yR8IQvMLfC0WKQqrHu5ZzXTH4NO3CwGWSlTY74kE91zXB5mwWAx1jig+UXYc2w4RkVhy0//lOmVya/PEepuuTTI4+UJwC7qbVlh5zfhj8oTNUXgN0AOc+Q0/WFPl1aw5VV/VrO8FCoB15lFVlpKaQ1Yh+DVU8ke+rt9Th0BCHXe0uZOEmH0nOnH/0onD
出现上图代表已经激活成功。
在PyCharm内添加WSL-Python解释器
英文版:<No interpreter>👉Add New Interpreter👉On WSL...
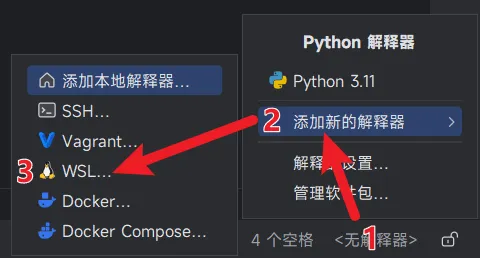
此时PyCharm会自动找到WSL并连接。
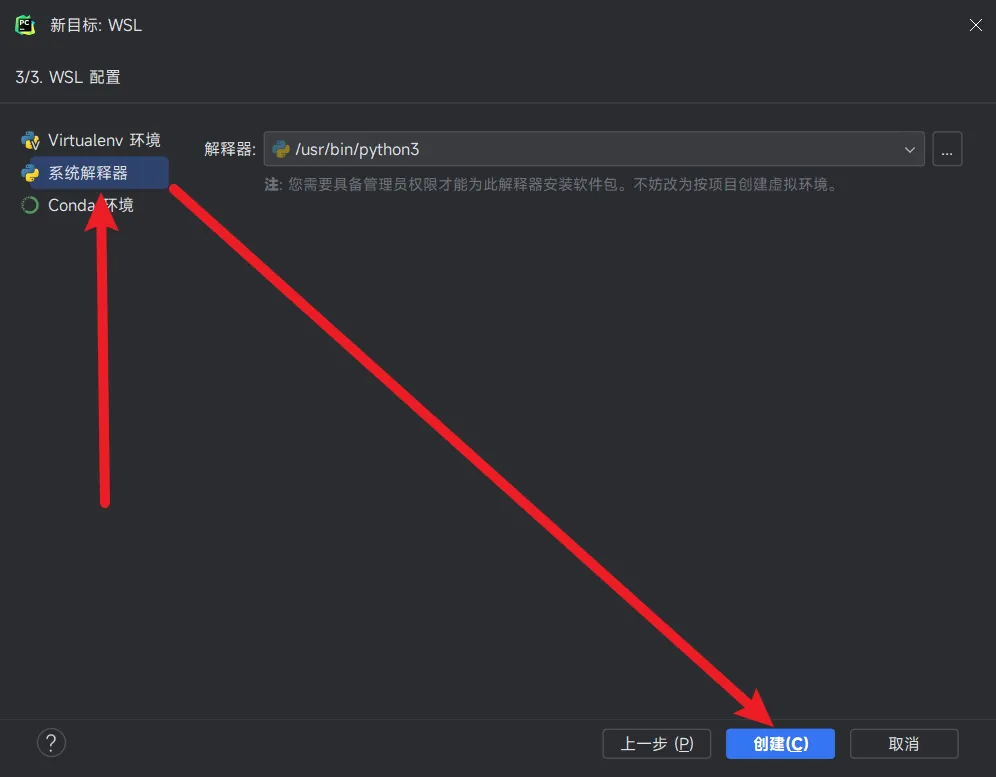
将鼠标移到带有红色波浪线的pyspark上,会出现提示安装软件包的按钮,点一下即可安装。
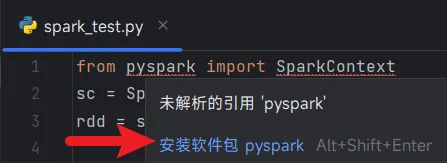 测试一下spark代码,正常运行。
测试一下spark代码,正常运行。
5.相关问题或相关教程
datanode/namenode...没有运行
这是因为没有设置自启动且也没有手动启动导致的。
手动启动方法:(Win+R运行ubuntu或wsl)
sudo service ssh start
start-all.sh
jps 如果显示以上内容,则代表启动成功。否则请看【jps查看运行状态缺少datanode/namenode】
如果显示以上内容,则代表启动成功。否则请看【jps查看运行状态缺少datanode/namenode】
将它们添加到系统自启动可以彻底解决此问题:
echo "sudo service ssh start" > /tmp/start_env.sh
echo "/usr/local/hadoop/sbin/start-all.sh" >> /tmp/start_env.sh
sudo mv /tmp/start_env.sh /etc/init.d/start_env.sh
sudo chmod +x /etc/init.d/start_env.shjps查看运行状态缺少datanode/namenode
# 先执行脚本停止所有服务
stop-all.sh
# 然后进行格式化
rm -rf /usr/local/hadoop/tmp/dfs/*
rm -rf /use/local/hadoop/data/*
cd /usr/local/hadoop
hdfs namenode -format
start-dfs.sh
jps此时应当可以正常运行 datanode, namenode, secondary namenode。
如果仍然不能运行,请手动搜索教程(cn.bing.com)。
向hdfs内上传文件
首先,需要确保你已经启动hadoop环境,见 【datanode/namenode...没有运行】
【方法一】通过WebUI进入文件管理器
浏览器打开 http://localhost:9870/explorer.html#/
【方法二】命令行上传
在你要上传的文件夹内,Shift+右键打开Powershell或cmd;
执行命令 wsl 进入WSL,并会自动cd到当前文件夹。
使用命令 ls 可以查看当前目录下的文件:

使用以下命令将其上传到 hdfs 根目录:
hdfs dfs -put seafood.txt /上传后可以使用以下命令查看hdfs根目录的文件:
hdfs dfs -ls /
6.WSL2配置kafka
前往官方网站下载kafka安装包:Apache Kafka
务必下载scala-2.12版本!
安装kafka
找一个合适的地方放置下载好的tar文件,然后在此处打开命令行窗口。(Shift+右键)
wsl
tar -xzvf kafka_2.12-3.6.1.tgz
cd kafka_2.12-3.6.1/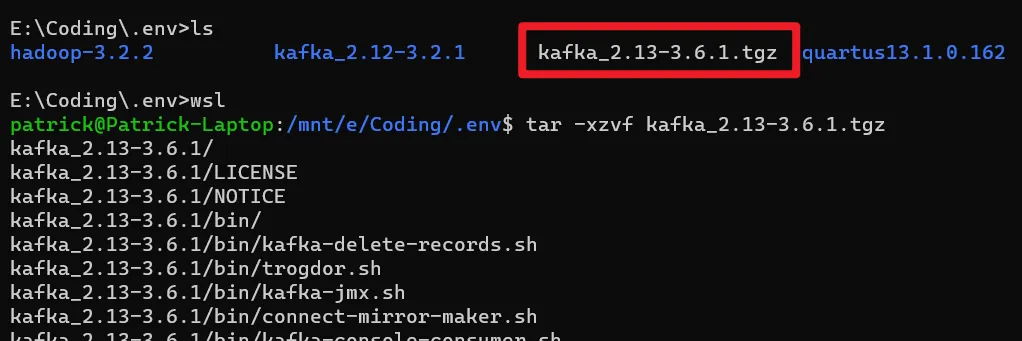
启动kafka
启动后,使用Ctrl+C快捷键/关闭窗口可关闭程序。
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties #启动zookeeper
bin/kafka-server-start.sh config/server.properties #启动kafka使用kafka
不要关闭先前创建的窗口,此处需要在kafka_2.12-3.6.1文件夹内另开一个命令行窗口,以下所有命令都使用相对路径。
若新开的是cmd/powershell窗口,需要输入wsl切换到WSL环境。
PPT给出的是适用于Windows的命令,若用于WSL,需要:
去掉\Windows
将 \ 改成 /,
将 .bat 改成 .sh
下面的命令已经修改好直接复制使用
创建Topic
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic bigdata
(其中bigdata可替换成自己的Topic名)
显示现有Topic
bin/kafka-topics.sh --list --bootstrap-server localhost:9092
Topic生产者
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic bigdataTopic消费者
消费者需要另开新窗口!同样需要在kafka环境下。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic bigdata --from-beginning在生产者中输入的内容,会出现在消费者中,测试通过。
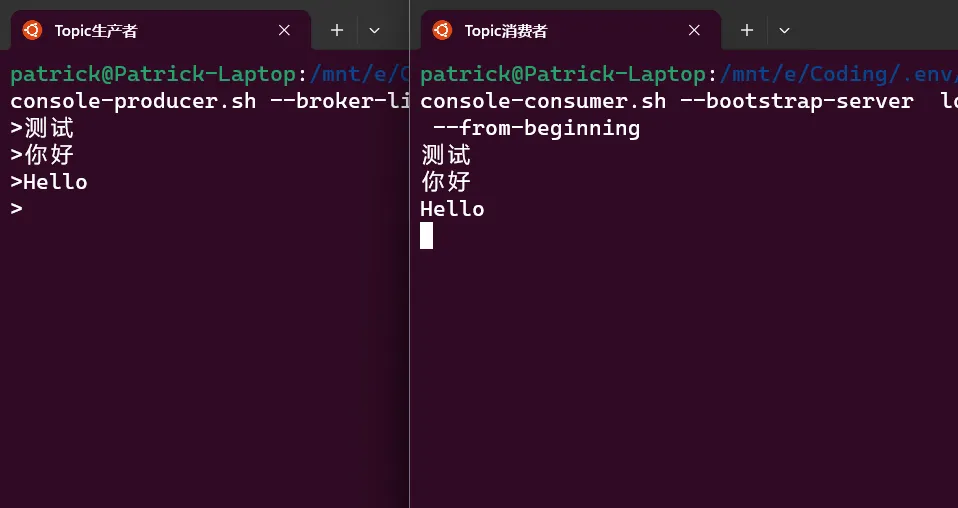
关闭Topic消费者
直接关闭消费者窗口.
7.Spark集成Kafka
移动kafka
sudo mv kafka_2.12-3.6.1 /usr/local/kafka使用pyspark自动安装依赖【推荐】
pyspark --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.0手动安装kafka集成组件【可能失败】
下载 Spark Integration For Kafka 0.10(MVNRepository)
移动到spark/jars内:
sudo mv spark-streaming-kafka-*.jar /usr/local/spark/jars
cd /usr/local/spark/jars
chmod -x spark-streaming-kafka-*.jar # 添加可执行权限然后在/usr/local/spark/jars目录下新建kafka目录,把/usr/local/kafka/libs下所有函数库复制到/usr/local/spark/jars/kafka目录下,命令如下
cd /usr/local/spark/jars
mkdir kafka
cd kafka
cp /usr/local/kafka/libs/* .然后,修改 Spark 配置文件,命令如下
cd /usr/local/spark/conf
sudo nano spark-env.sh将以下内容添加到文件末尾:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath):/usr/local/spark/jars/kafka/*:/usr/local/kafka/libs/*
export PYSPARK_PYTHON=/usr/bin/python3.10(其中Python版本根据自己安装版本修改)
然后,修改 pySpark 配置文件,命令如下
sudo nano /usr/local/spark/bin/pyspark然后通过pip安装kafka组件
pip install kafkaSLF4J检测到多个jar文件的解决方法
由于在这里使用的是spark,直接将hadoop和kafka内置的slf4j改名
mv /usr/local/hadoop/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar /usr/local/hadoop/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar.bak
mv /usr/local/kafka/libs/slf4j-reload4j-1.7.36.jar /usr/local/kafka/libs/slf4j-reload4j-1.7.36.jar.bak- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝





