

从0开始配置WSL开发环境(Hadoop,Spark)
本文最后更新于 2024-02-24,当前距离文章发布(更新)已经超过365天,文章内容可能已经过时,请注意甄别。
1.初识WSL-Ubuntu
从开始菜单打开已经安装好的Ubuntu,会自动进行安装
安装好后,会要求设置UNIX用户名和密码。
此密码需要牢记,且最好不要太过简单。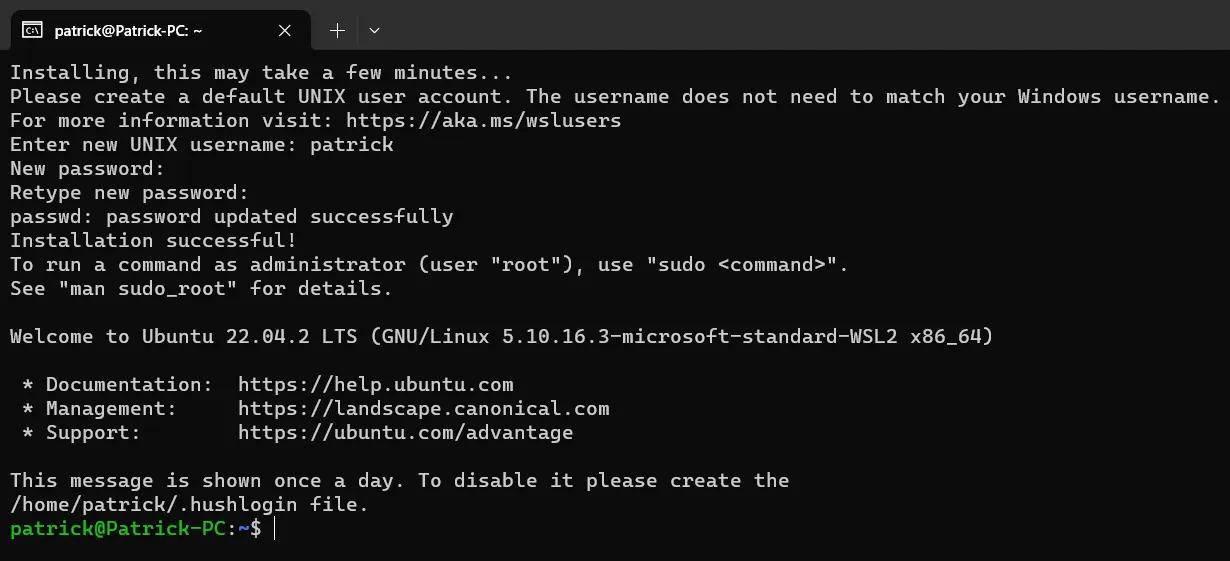
一个题外话:
启动WSL子系统的方法有非常多,包括但不限于:
开始菜单点击Ubuntu快捷方式
cmd/powershell 中使用wsl命令
cmd/powershell 中使用ubuntu命令
Windows Terminal中手动新建WSL子系统的窗口
......
2.修改软件源、安装软件包、修改系统配置
接下来,修改Ubuntu的软件包源为USTC,也可以使用其他任何你喜欢的国内镜像源(以下命令通用现代Ubuntu发行版):
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
sudo sed -i 's@//.*archive.ubuntu.com@//mirrors.ustc.edu.cn@g' /etc/apt/sources.list修改完成后,执行软件源缓存更新和软件包更新:
sudo apt update
sudo apt upgrade -y在使用apt安装软件包前,需要先修改一些配置,否则必定会在安装openssh-server时遇到问题。
cd /usr/lib/wsl
sudo mkdir lib2
sudo ln -s lib/* lib2
sudo ldconfig
sudo sed -i 's#/usr/lib/wsl/lib#/usr/lib/wsl/lib2#' /etc/ld.so.conf.d/ld.wsl.conf
echo -e "[automount]\nldconfig = false" | sudo tee -a /etc/wsl.conf使用apt工具安装一些必要的软件包:
sudo apt install python3 python3-pip openjdk-8-jdk openssh-server -y修改pip软件源为清华大学镜像,并更新pip
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install pip --upgrade运行sshserver,并用 ssh-keygen 生成密钥并添加为信任,避免每次ssh连接都提示:
sudo service ssh restart
ssh localhost
# 运行上一条之后,依此输入 yes ,你的密码。
# 成功进入 ssh 后,输入 exit 回车 退出。
cd ~/.ssh/
ssh-keygen -t rsa
# 执行完上一条指令会询问你一些参数,一直按回车直到没有新行弹出即可继续下一条命令
cat ./id_rsa.pub >> ./authorized_keys3.安装Hadoop, Spark
下载hadoop、spark软件包(或使用【3.b.3 Hadoop和Spark软件包】提供的文件)
Hadoop清华镜像下载:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
Spark清华镜像下载:https://mirrors.tuna.tsinghua.edu.cn/apache/spark/
下载spark时,推荐下载 without-hadoop版本,避免版本不匹配出错。
教程编写时,最新的版本是hadoop-3.3.6和spark-3.5.0,以此为例,进行解压操作:
# 在你下载 hadoop...tar.gz 和 spark....tgz 的目录打开终端,并进入WSL
sudo tar -xzf hadoop*.tar.gz -C /usr/local
sudo tar -xzf spark*.tgz -C /usr/local然后,进入 /usr/local,对文件夹进行更名,并给自己添加权限
cd /usr/local
sudo mv hadoop-* hadoop
sudo mv spark-* spark
sudo chown -R 你的用户名 hadoop
sudo chown -R 你的用户名 spark执行 ls ,此时你的文件夹内应当有以下文件

接下来,添加环境变量
sudo nano ~/.bashrc
# 在文件顶部,粘贴以下内容:(nano编辑器可以直接使用Ctrl-V粘贴)
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_LIBRAY_PATH=/usr/local/hadoop/lib/native
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:${SPARK_HOME}/bin
# 粘贴好后,使用快捷键 Ctrl+S 保存, Ctrl+X 退出编辑器
source ~/.bashrc
# 使环境变量立即生效修改好后的文件看起来是这样:
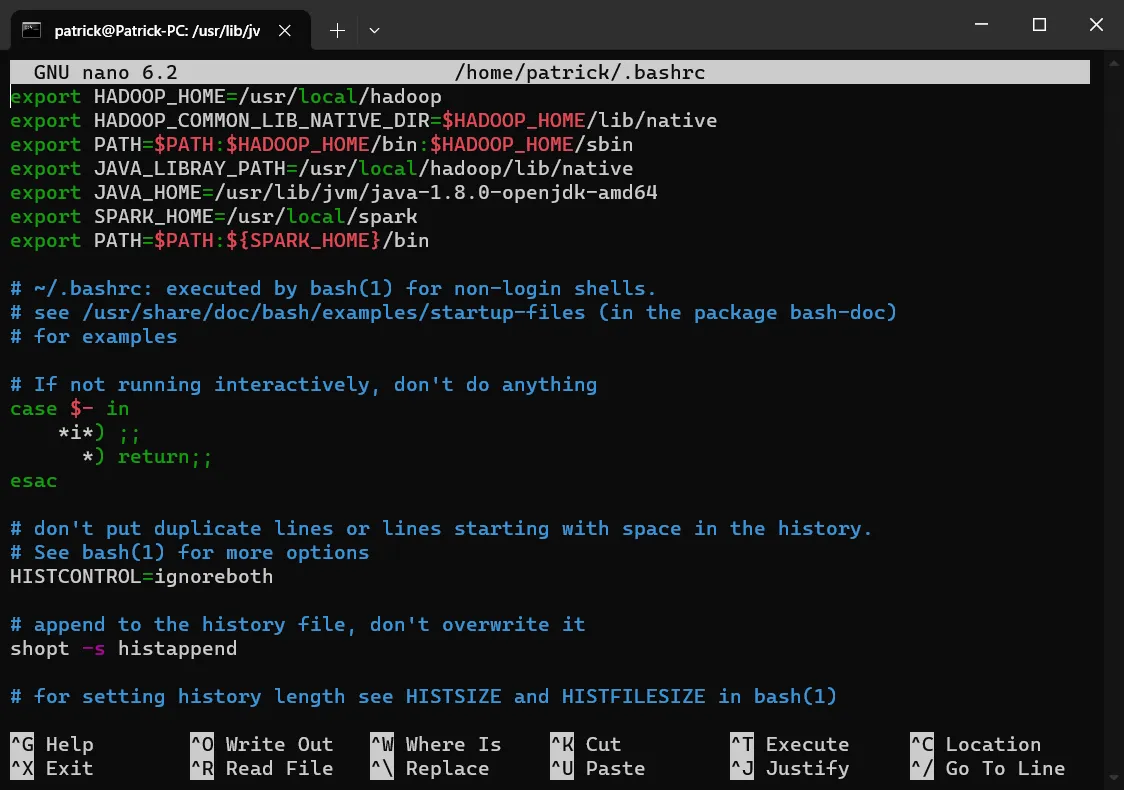
下面,执行命令测试一下是否正确配置:
hadoop version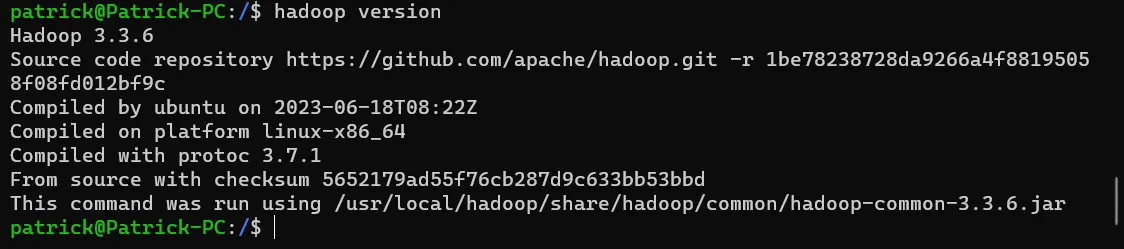
如果正确配置,Hadoop命令应当能够执行。
4.配置Hadoop伪分布式
进入到Hadoop的配置目录,然后
修改hadoop-env.sh
cd /usr/local/hadoop/etc/hadoop
sudo nano hadoop-env.sh
# 将以下内容粘贴到文件内并保存。
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"就像这样:
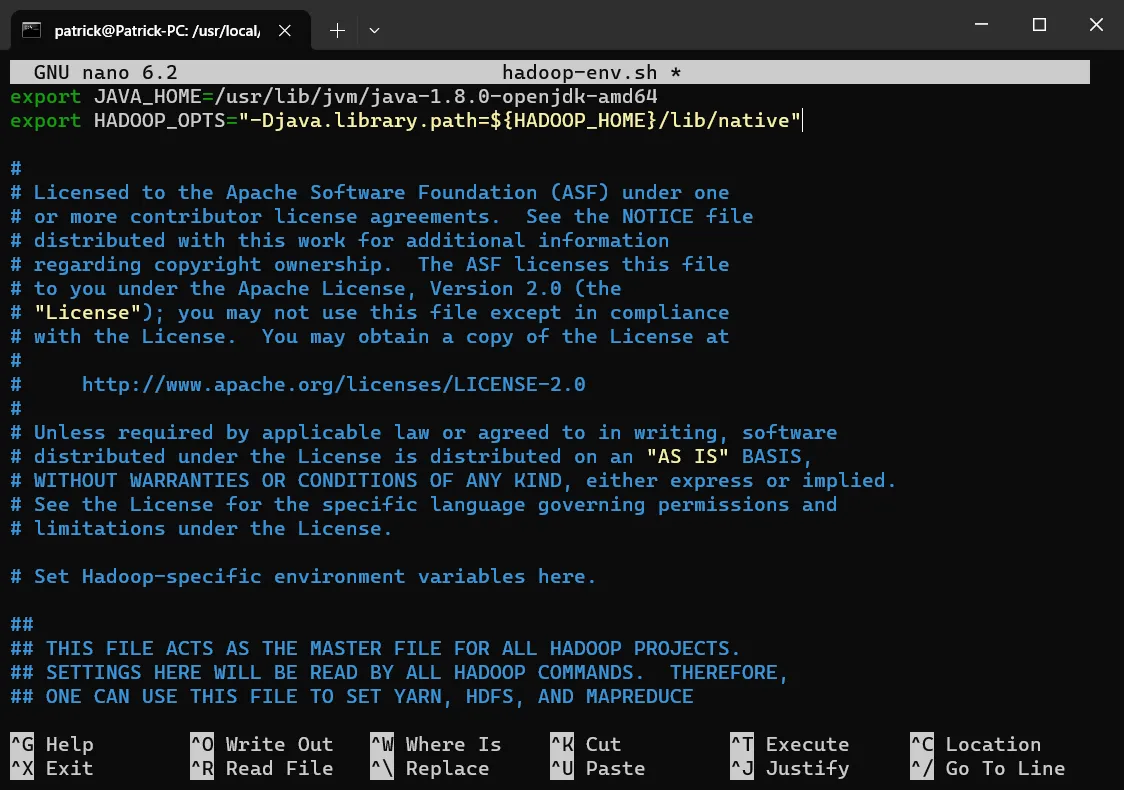
修改core-site.xml
sudo nano core-site.xml
# 将以下内容粘贴到<configuration> </configuration>的中间并保存。
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>就像这样:
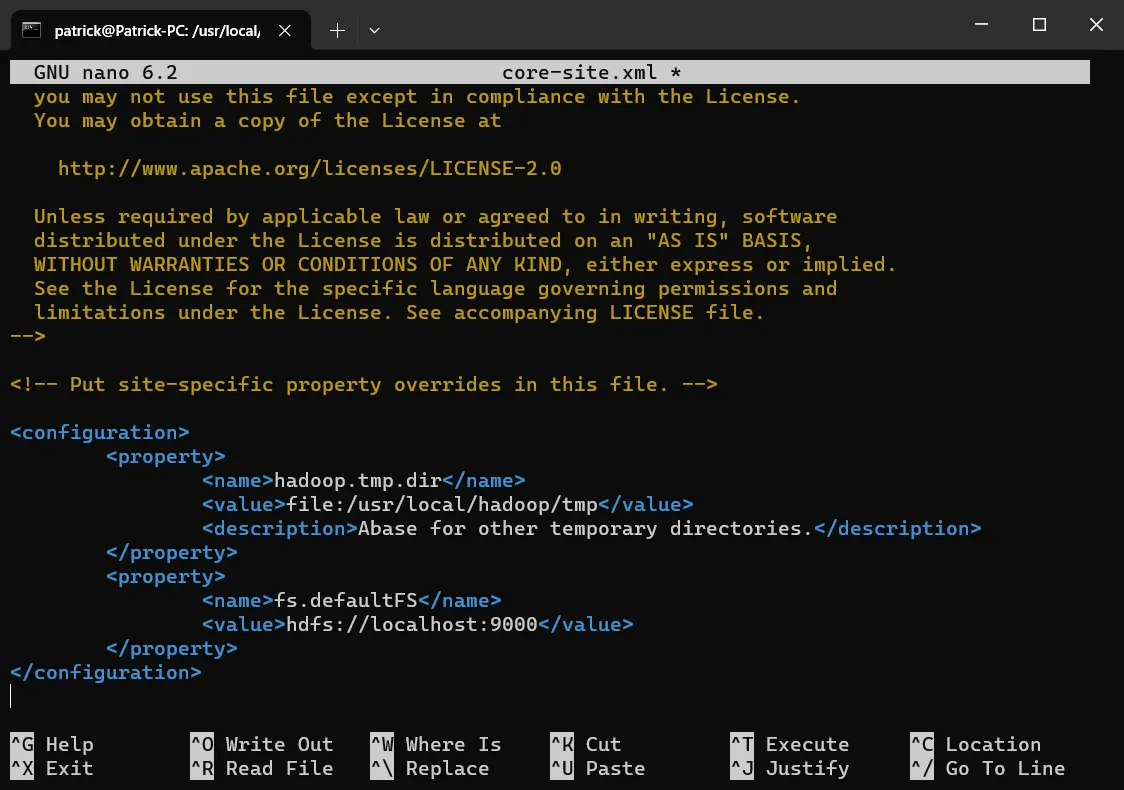
修改hdfs-site.xml
sudo nano hdfs-site.xml
# 将以下内容粘贴到<configuration> </configuration>的中间并保存。
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>就像这样:
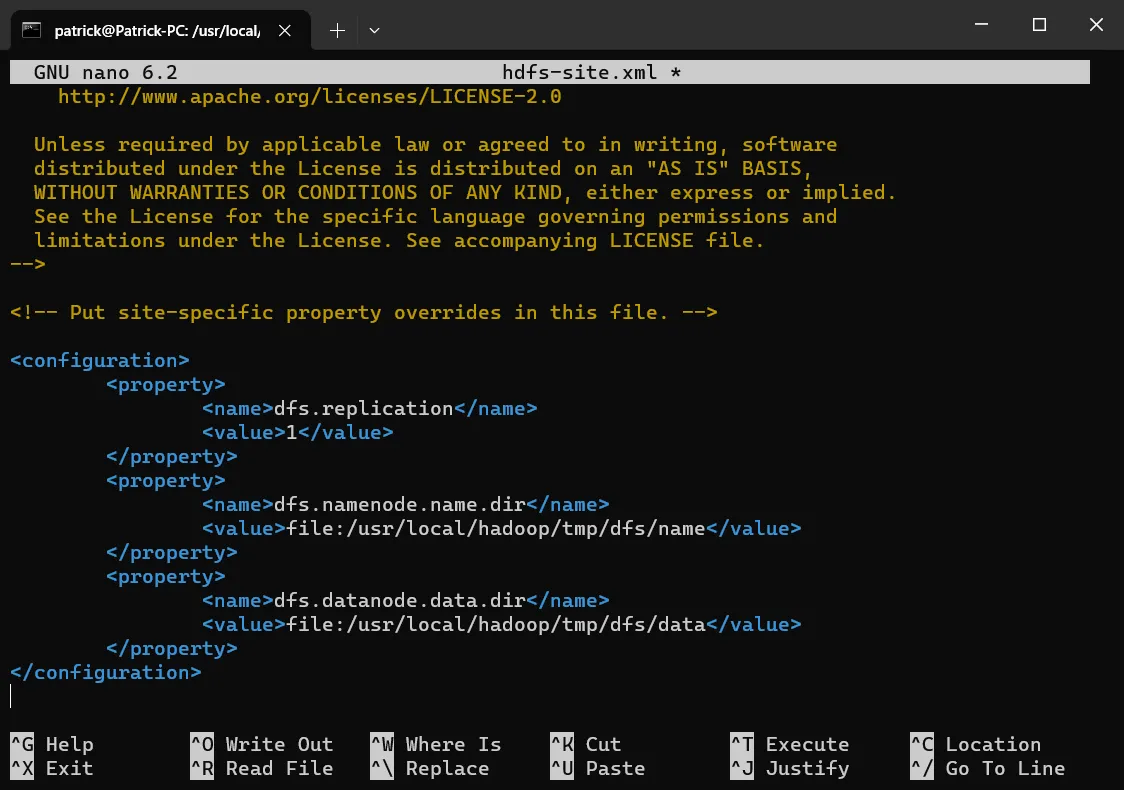
测试HDFS
#启动ssh
sudo service ssh start
#格式化Namenode
hdfs namenode -format
#启动dfs
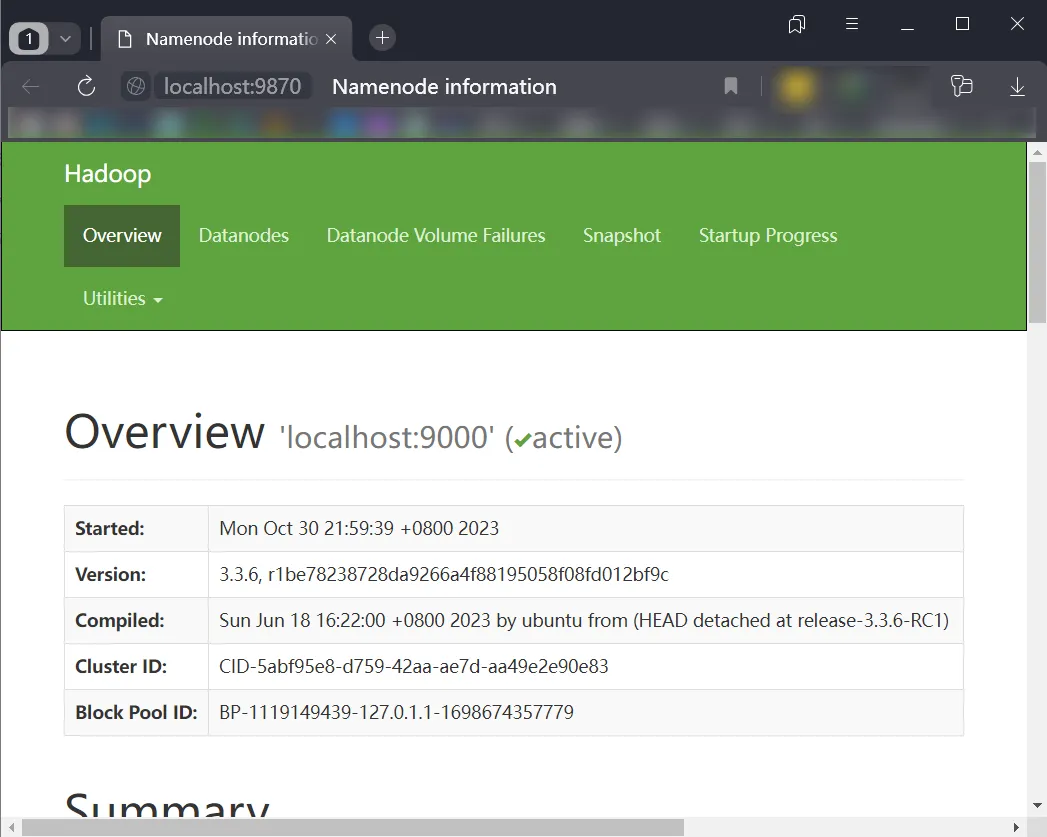
/usr/local/hadoop/sbin/start-dfs.sh可以使用jps来查看运行状态,如果正常,应该显示以下四个项:

并且,浏览器访问 http://localhost:9870也应该能显示WebUI:
YARN单机配置
修改 mapred-site.xml
sudo nano mapred-site.xml
# 将以下内容粘贴到<configuration> </configuration>的中间并保存。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>修改 yarn-site.xml
sudo nano yarn-site.xml
# 将以下内容粘贴到<configuration> </configuration>的中间并保存。
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>查看资源管理页面
/usr/local/hadoop/sbin/start-all.sh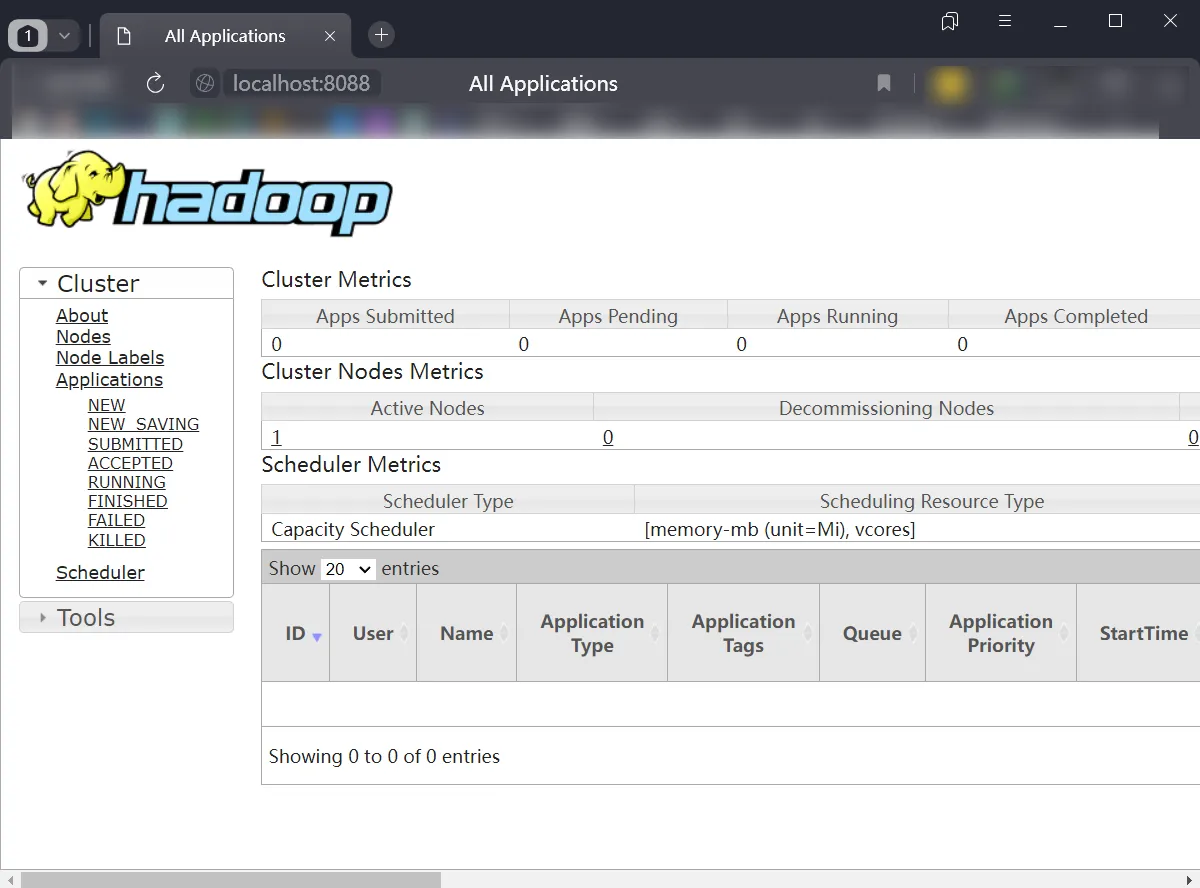
如果配置正确,这个网页应当正常显示。
5.配置Spark
# 进入spark配置文件夹
cd /usr/local/spark/conf
# 编辑 spark-env.sh
sudo cp spark-env.sh.template spark-env.sh
sudo nano spark-env.sh
# 将以下内容粘贴到文件头并保存。
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
# 启动Spark
/usr/local/spark/sbin/start-all.sh打开 http://localhost:8080 可以打开Spark的WebUI
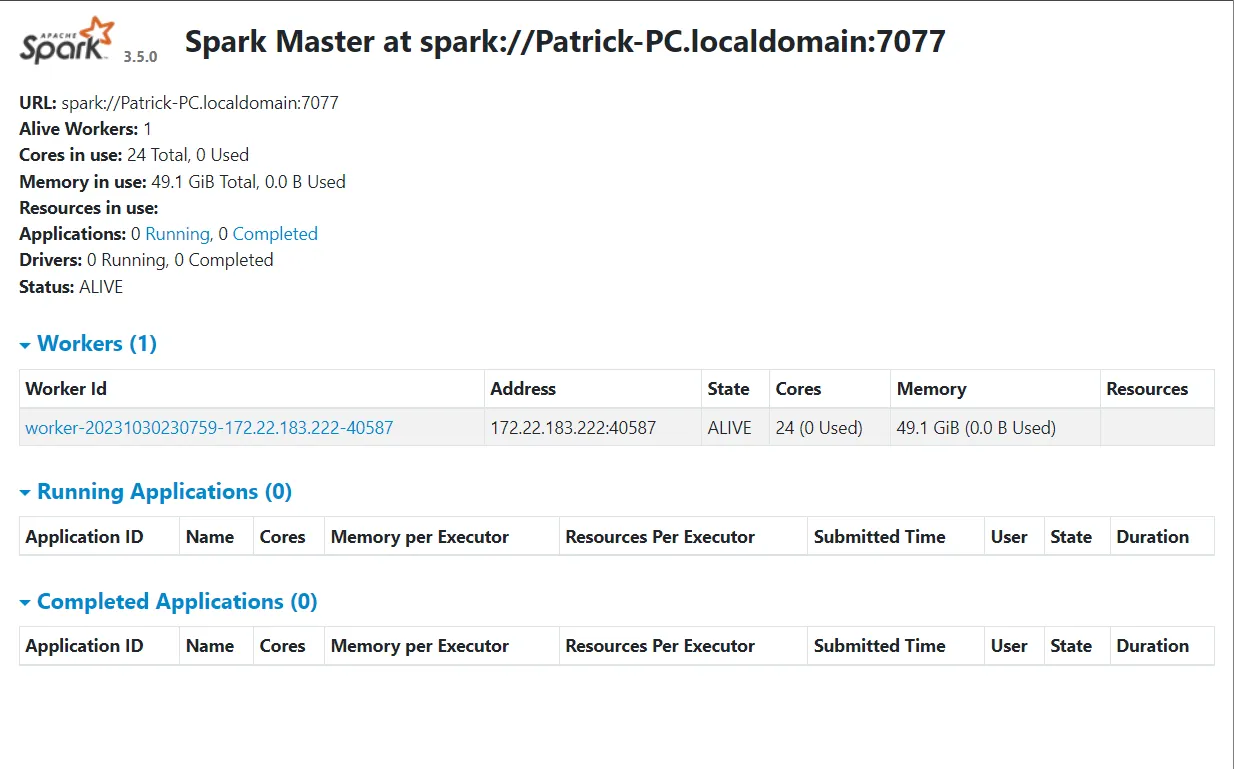
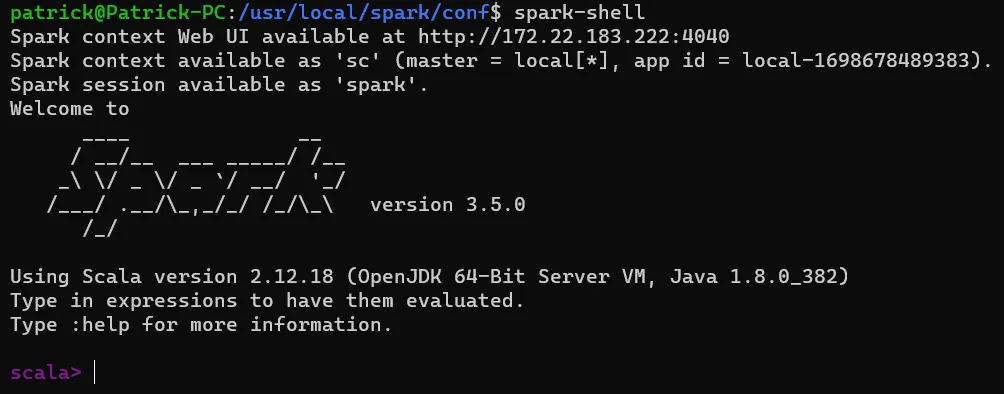
输入spark-shell或者pyspark,可以进入Spark命令行

如果您从《安装 WSL2-Ubuntu 并配置 Hadoop,Spark 环境》点进本文章,那么您现在可以返回原文章继续阅读了。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝





