

记一次单片机源码由GB2312改为UTF8编码导致OLED汉字显示异常的解决过程
本文最后更新于 2024-03-29,当前距离文章发布(更新)已经超过365天,文章内容可能已经过时,请注意甄别。
起因
从stc32上下载的OLED显示源码,其中包含汉字的显示部分(伏笔),不过下载下来一看全是乱码(因为VSCode默认是UTF8编码,且默认不开自动识别编码功能),手动切换为GB2312才正常。
后来给VSCode打开了自动识别编码(Auto Guess Encoding),问题大体上解决了,但是对于部分汉字含量较少的源码,仍然有可能识别为UTF8,例如下图的font.h
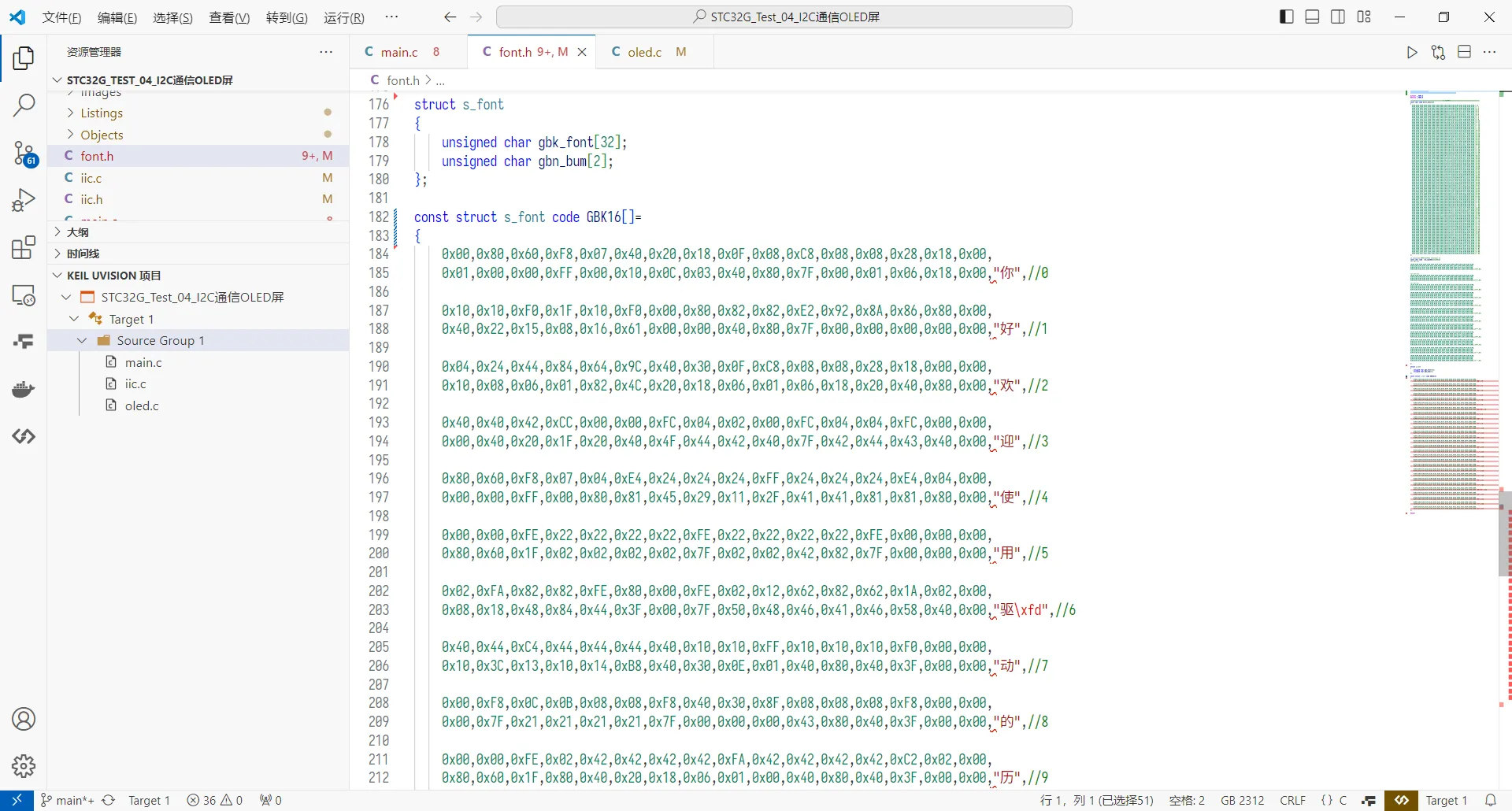 于是本着“遇到问题就解决避免以后再出现”的原则,把所有源码咔咔一顿操作全部转换成了UTF8编码格式。
于是本着“遇到问题就解决避免以后再出现”的原则,把所有源码咔咔一顿操作全部转换成了UTF8编码格式。
问题
这一转换不要紧,一编译,嘿,直接炸了: 啊?
啊?
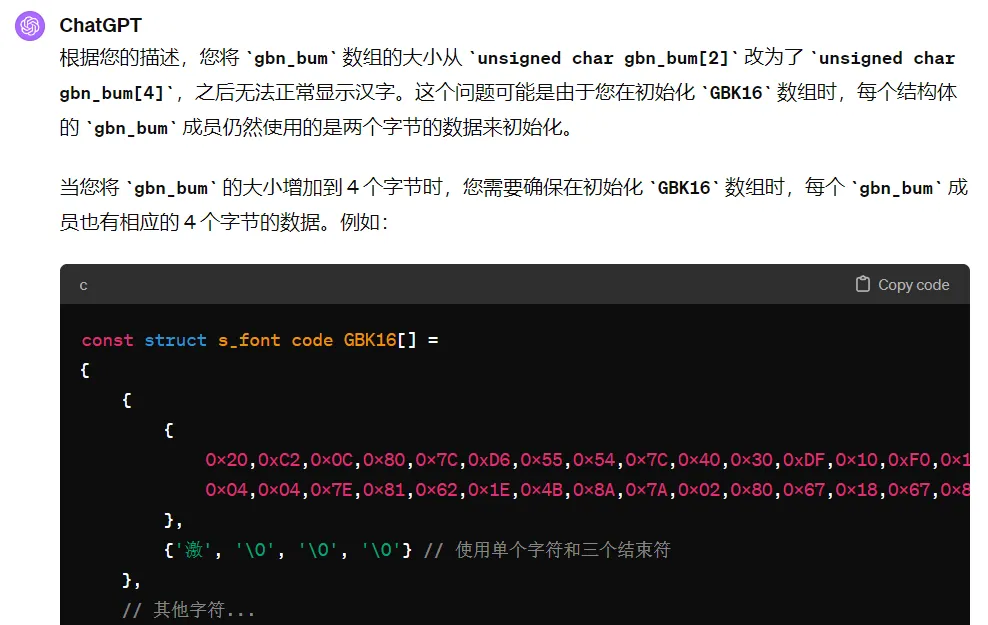
询问万能的ChatGPT,他说gbn_bum太小了:
 这是修改前的源码:
这是修改前的源码:
struct s_font
{
unsigned char gbk_font[32];
unsigned char gbn_bum[2];
};
const struct s_font code GBK16[]=
{
0x00,0x80,0x60,0xF8,0x07,0x40,0x20,0x18,0x0F,0x08,0xC8,0x08,0x08,0x28,0x18,0x00,
0x01,0x00,0x00,0xFF,0x00,0x10,0x0C,0x03,0x40,0x80,0x7F,0x00,0x01,0x06,0x18,0x00,"你",//0
// ...其他字符
};改成gbn_bum[4]后,确实不报错了,但是汉字显示也全G了:

不死心,继续走弯路:

一顿操作猛如虎,一看显示二百五,汉字还是一个都出不来。
就算打开未经修改的源码,拷贝过来保存编译,还是一样的问题。
这个时候问题就很明显了——就是文件编码的锅。
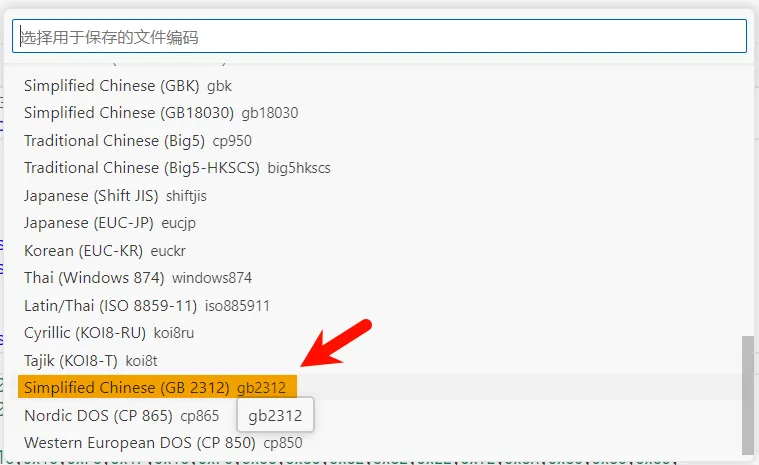 将涉及到汉字显示的
将涉及到汉字显示的font.h保存为GB2312编码(gbn_bum改回了[2]):
编译!没error,只有warning!
下载!成功!
启动!寄!

经过谨慎但又完全不缜密的思考,终于想起来main.c里边也有汉字(调用显示汉字的函数),而它的编码目前也是错误的……
把main.c转换回GB2312,编译下载,总算是恢复正常了:

总结
这个故事告诉我们,没事儿不要瞎改编码,尤其是涉及到汉字这种特殊玩意儿的时候……
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
赞赏者名单
因为你们的支持让我意识到写文章的价值🙏
本文是原创文章,采用 CC BY-NC-SA 4.0 协议,您可以在不商用的情况下,免费转载或修改本文内容,完整转载请注明来自 Patrick's Blog

评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果